
La democratización tecnológica, sobre todo en el ámbito de la Ciencia de Datos, ha puesto al alcance de muchos profesionales las herramientas necesarias para realizar una manipulación óptima de los datos que permita extraer ideas y patrones necesarios para la mejora de procesos empresariales en las áreas de Marketing, Logística, RRHH, Comercial…
Pero bien es cierto que, aunque estas tecnologías sean accesibles, se debe de tener un elevado conocimiento de todo su entorno tecnológico y matemático para que las conclusiones extraídas sean fieles a la realidad y no sean erróneas.
Para demostrar lo anteriormente expuesto, me gustaría detallar un proyecto basado en Ciencia de Datos que realizamos para una reconocida empresa del sector de los seguros.
Dicha empresa contaba con una base de datos de clientes y otra de posibles clientes. La base de datos de clientes representaba en tamaño el 2% de la de posibles clientes.
La estrategia de captación consistía en un Call Center que iba focalizando los esfuerzos de captación según una investigación previa de cada una de las empresas a la que iban a contactar. Contando con el tamaño tan grande que tenía la base de datos de posibles clientes, esta estrategia era poco efectiva y suponía un gasto de recursos muy elevados.
Por eso mismo, en APACHE ofrecimos a esta empresa realizar una Clusterización de la base de datos y un Lead Scoring, donde utilizamos técnicas de Machine Learning para ayudar al Call Center a focalizar los esfuerzos según el Cluster realizado y la nota arrojada por los diferentes algoritmos que utilizamos.
Además, la base de datos cuenta con una gran cantidad de valores nulos, por lo que se utilizaron también técnicas de Machine Learning para completar esos datos, realizando inferencia estadística y consiguiendo entregar al cliente un conjunto de datos enriquecido donde los valores nulos serían completados.
¿Cómo lo hicimos? Aquí abajo os lo explicamos:
Proceso
Antes de comenzar, tengo que aclarar que el proyecto fue mucho más largo, se utilizó una gran cantidad de procesos y se verificó los resultados para asegurar que estos se acercaran a la realidad, por lo que habrá pasos que no especifiquemos completamente y únicamente aportamos una aproximación como ejemplo de lo que fue el proyecto completo.
Para la realización del ejemplo, vamos a utilizar una base de datos artificial que creamos a través de datos sintéticos, pero desarrollada de una forma muy precisa para que los datos se asemejara lo máximo posible a la realidad.
Importación de datos y análisis de variables
En primer lugar, importamos las librerías necesarias para realizar el proyecto.
import pandas as pd
import numpy as np
import missingno as msno
import matplotlib.pyplot as plt
%pylab
%matplotlib inline
import seaborn as sns
from sklearn.preprocessing import OrdinalEncoder
from fancyimpute import KNN
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score, precision_score, recall_score, roc_curve
from sklearn.ensemble import RandomForestClassifier
Como podemos ver, importamos librerías para limpieza de datos, visualización de datos y Machine Learning.
En segundo lugar, el cliente nos envió mediante un SFTP los datos anonimizados donde la información tenía la siguiente apariencia:
df = pd.read_csv("ruta")
df.head()

En el proyecto real, los datos eran bastante más complejos, tuvimos que realizar una gran labor de limpieza para poder aportar uniformidad, pero para este artículo nos ahorraremos esa parte.
Al revisar la forma de los datos nos encontramos con lo siguiente:
df.shape
Contamos con 19983 registros divididos en 10 columnas, las columnas son las siguientes:
- id: Identificador que utiliza el cliente para identificar a la empresa, que además permitirá más adelante relacionar los resultados con las bases de datos, debido a que no se nos proporcionó ni el CIF ni el nombre de la empresa.
- n_empleados: Variable categórica que especifica diferentes grupos relacionados con el número de empleados de cada empresa.
- facturacion: Variable categórica que especifica los intervalos de facturación.
- forma_juridica: Variable categórica donde, como el mismo nombre indica, se trata de la forma jurídica de la empresa.
- sector_empresa: Variable categórica, aquí nos encontramos con el sector dentro del que opera cada empresa.
- TAMAÑO: Variable categórica donde se especifica en grupos el tamaño de la empresa.
- ACTIVIDAD: Variable categórica que indica la actividad que realiza cada empresa.
- Capital: Variable categórica que muestra el intervalo de Capital de cada empresa.
- Score: Variable numérica, nota que le aplicaba nuestro cliente al crear el Lead dentro del CRM. Se basa en criterios internos.
- Client: Variable binaria. Aquí nos encontraremos un 1 para las empresas que son cliente, un 0 para las empresas que han dejado de ser cliente y un NaN para las empresas que son prospects, es decir, que todavía ni son cliente ni han dejado de ser cliente. En este ejemplo contaremos con 3600 registros que son 0 o 1 y 16383 que son NaN.
Limpieza de valores nulos (enriquecimiento de la base de datos)
A continuación, os mostramos la técnica utilizada para realizar la limpieza de valores nulos.
En primer lugar, utilizamos una de mis librerías favoritas de limpieza de datos: missingno, para poder ver de forma visual en qué columnas faltan datos.
msno.matrix(df)
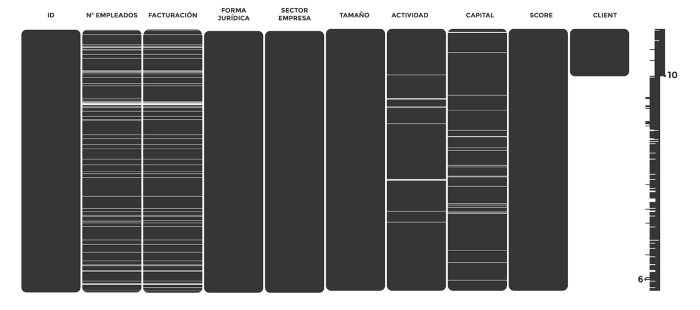
Como vemos, las columnas n_empleados, facturación, ACTIVIDAD y Capital cuentan con valores nulos, esto lo remediamos a continuación. Client también tiene valores nulos, pero se debe a que los NaN son posibles clientes, por lo que de momento separaremos esa columna del DataFrame.
df = df.drop(columns = "Client")
En este caso, para la creación del modelo necesitamos tener todas las empresas, por lo que no podemos eliminar ningún registro. Al ser empresas diferentes, tampoco podemos utilizar técnicas clásicas como el backfill, bfill, ffill…
Por ello, para solventar esta problemática, decidimos aplicar el primer modelo de Machine Learning: KNN K-Nearest Neighbors. Con este método de clasificación supervisado, pudimos estimar, gracias a una función de densidad de probabilidades, los valores que faltaban en función de sus “vecinos” del espacio vectorial, es decir, este algoritmo buscaba similaridades entre diferentes registros y rellenaba los valores nulos en función de una inferencia basada en registros similares.
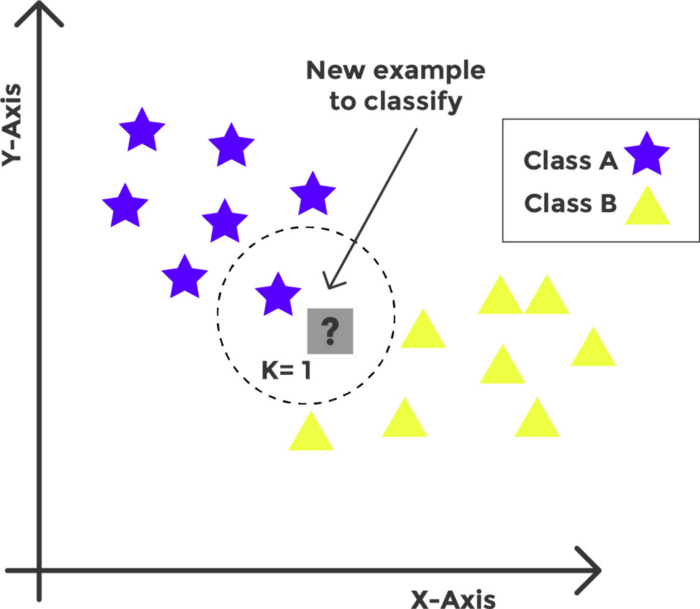
Por lo que aplicaremos lo siguiente:
Encoder
ordinal_enc_dict = {}for col_name in df:
ordinal_enc_dict[col_name] = OrdinalEncoder()
col = df[col_name]
col_not_null = col[col.notnull()]
reshaped_vals = col_not_null.values.reshape(-1, 1)
encoded_vals = ordinal_enc_dict[col_name].
fit_transform(reshaped_vals)
df.loc[col.notnull(), col_name] = np.squeeze(encoded_vals)
KNN_imputer
KNN_imputer = KNN()df.iloc[:, :] = np.round(KNN_imputer.fit_transform(df))
for col_name in df:
reshaped = df[col_name].values.reshape(-1, 1)
df[col_name] = ordinal_enc_dict[col_name].
inverse_transform(reshaped)
Con esto, se realiza una inferencia con la que se rellenarán los datos y conseguiremos el siguiente resultado.

Como podemos ver, los datos han sido imputados en su totalidad, consiguiendo una base de datos completa.
Clustering
Ahora que tenemos los datos completos en su 100%, se procede a aplicar la segmentación de los datos.
Debemos tener en cuenta que la mayoría de los datos son categóricos, esto complica bastante el desarrollo de los diferentes algoritmos. Los datos originales contienen también columnas numéricas, por lo que optamos por utilizar el algoritmo K-Means, creando variables dummies; otra alternativa que también valoramos fue la utilización del modelo K-Medoids, pero los tiempos de procesamiento eran muy elevados y no notamos que los resultados fueran muy diferentes.
En primer lugar, deberemos de averiguar el número óptimo de Clusters, y para ello emplearemos la técnica de Silhouette.
Para ello, antes generamos las variables dummies.
df_dummies = pd.get_dummies(df, columns ["n_empleados","facturacion","forma_juridica",
"sector_empresa", "TAMAÑO","ACTIVIDAD","Capital"])
Y a continuación aplicamos la técnica de Silhouette.
def plot_sillhouette(blobs, figure_name, max_k = 10, n_init = 15):
sillhouette_avgs = []
for k in range(2, max_k):
kmean = KMeans(n_clusters = k, n_init = n_init).fit(blobs)
sillhouette_avgs.append(silhouette_score(blobs,
kmean.labels_))
plot(range(2, max_k), sillhouette_avgs)
title(figure_name)plot_sillhouette(df_dummies, 'Sillhouette')
Obteniendo los siguientes resultados:
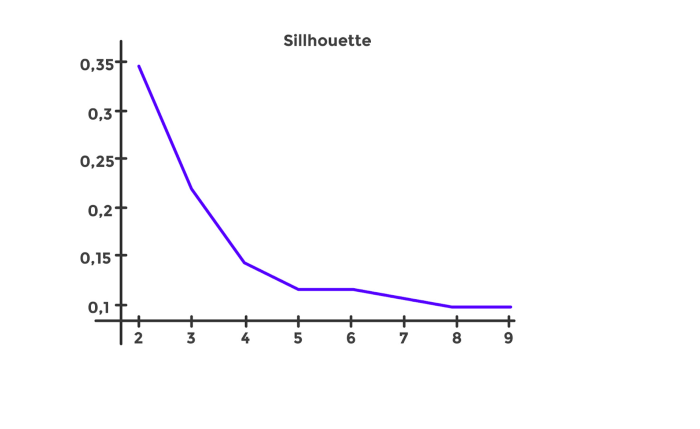
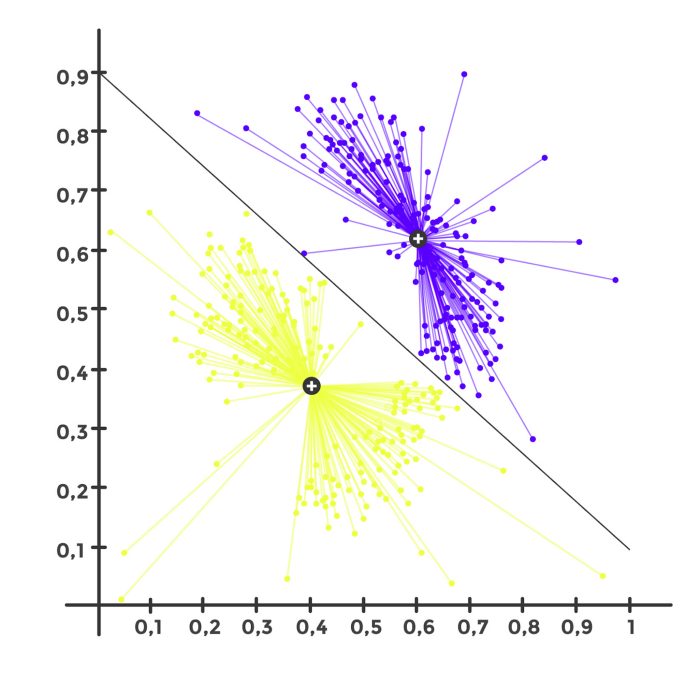
Como podemos ver, el número óptimo de Clusters es 2. Podríamos ahondar un poco más y realizar Sub-Clusters dentro de cada Cluster, pero en este caso lo dejaremos así.
Como sabemos que el número óptimo es 2, procederemos a aplicar el algoritmo K-Means para obtener los Clusters.
kmeans = KMeans(n_clusters = 2, init="k-means++", max_iter = 300, n_init = 10)
y_kmeans = kmeans.fit_predict(df_dummies)
y_kmeans
Finalmente, insertamos el array obtenido dentro de nuestro DataFrame imputado.
df.insert(0, 'Cluster', y_kmeans)
Veamos la distribución de los datos:
ax = sns.countplot(x="Cluster", data=df, order = df['Cluster'].value_counts().index)
plt.ylabel("Nª Empresas")
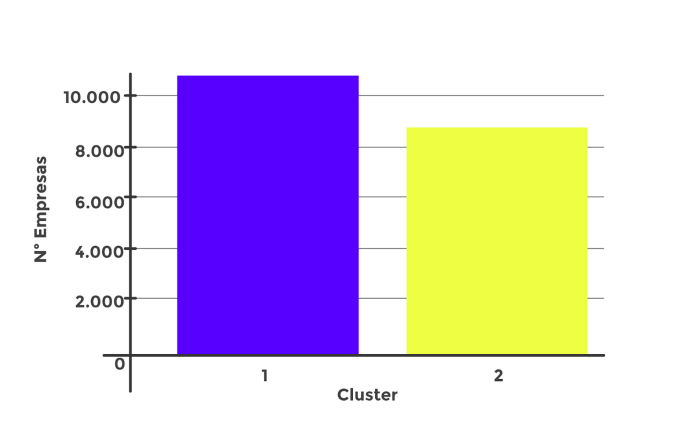
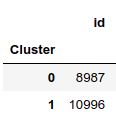
Hemos obtenido el siguiente número de datos por Cluster:
df.groupby('Cluster').count()
Entrenamiento del modelo de Clasificación para el Lead Scoring
Una vez que contamos con los Clusters, la siguiente fase es la del Lead Scoring, donde aplicaremos modelos de clasificación para generar notas por cada empresa y así facilitar la labor del Call Center, para que se centren en los usuarios más proclives a convertirse en clientes.
Para la creación del modelo utilizaremos los primeros 3600 registros, ya que estos son los que tienen los datos de si la empresa es cliente o no, para ello simplemente aplicaremos lo siguiente:
df = df[df_prueba['Client'].notnull()]
En segundo lugar, volveremos a generar variables dummies y crearemos la siguiente función para medir los resultados de los modelos:
def metricas_modelos(y_true, y_pred):
# Obtención de matriz de confusión
confusion_matrix = confusion_matrix(y_true, y_pred)print('La matriz de confusión es ')
print(confusion_matrix)print('Precisión:', accuracy_score(y_true, y_pred))
print('Exactitud:', precision_score(y_true, y_pred))
print('Exhaustividad:', recall_score(y_true, y_pred))
print('F1:', f1_score(y_true, y_pred))false_positive_rate, recall, thresholds = roc_curve(y_true, y_pred)
roc_auc = auc(false_positive_rate, recall)print('AUC:', auc(false_positive_rate, recall))plot(false_positive_rate, recall, 'b')
plot([0, 1], [0, 1], 'r--')
title('AUC = %0.2f' % roc_auc)
Dividimos los datos en conjunto de entrenamiento y test:
X = df.drop(columns=["id","Client"])
y = df.pop("Client")
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 3)
Y comenzamos a aplicar los algoritmos de clasificación para ver cuáles nos devuelven los mejores resultados.
Finalmente, damos con el RandomForestClassifier, donde con sus parámetros ajustados obtenemos resultados muy interesantes.
rf_classifier = RandomForestClassifier(criterion = 'entropy',
n_estimators = 18,random_state = 1).fit(X_train, y_train)y_pred = rf_classifier.predict(X_train)print('Precisión:', accuracy_score(y_train, y_pred))
print('Exactitud:', precision_score(y_train, y_pred))
print('Exhaustividad:', recall_score(y_train, y_pred))

Las tres métricas están por encima del 86%, generando una precisión y especificidad muy buenas.
Además, analizamos la curva ROC:
false_positive_rate, recall, thresholds = roc_curve(y_train, y_pred)
roc_auc = auc(false_positive_rate, recall)print('AUC:', auc(false_positive_rate, recall))
plot(false_positive_rate, recall, 'b')
plot([0, 1], [0, 1], 'r--')
title('AUC = %0.2f' % roc_auc)
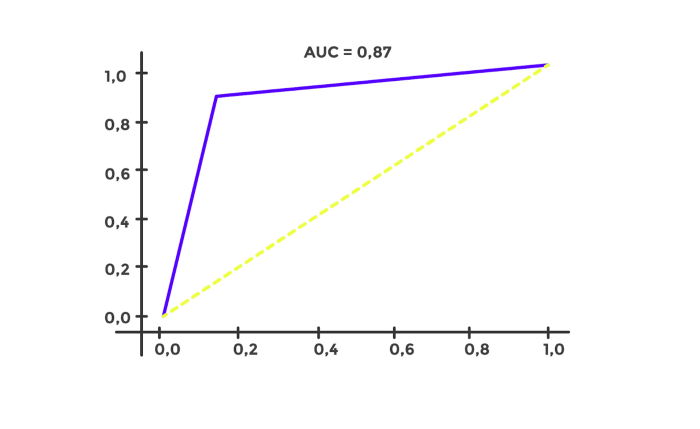
A continuación, se toma el DataFrame total, separándolo en conjunto X e y para aplicar el modelo en el conjunto total y conseguir los Score que queremos tener:
parameters = {'n_estimators' : 18, 'random_state' : 1, 'criterion' : 'entropy'}
model = RandomForestClassifier(**parameters)
model.fit(X, y)DefaultProba = model.predict_proba(df)
DefaultProba = DefaultProba[:,1]
Aplicando esto, el modelo nos devolverá un array con números entre 0 y 1, que básicamente son la probabilidad de que una empresa se convierta en cliente.
Con los resultados por empresa, estos datos se añaden al dataframe y se representan visualmente para ver la distribución de los datos:
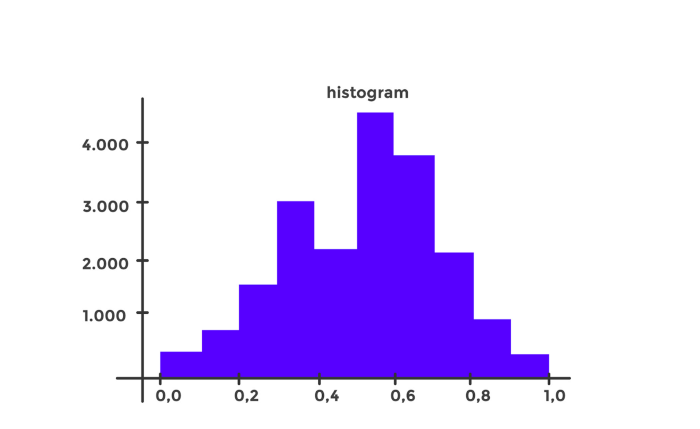
Como vemos, los datos se acumulan entre 0.5 y 0.7, pero los más interesantes serán aquellos que están más cerca de 1 es decir 0.8 y 0.9.
Para que la visualización sea más friendly, generamos Chunks y States, que básicamente lo que harán será agrupar a estas empresas según los resultados en notas del 0 al 10 y estados (Cold, Warm y Hot) para ayudar al Call Center a seleccionar a qué empresas llamar consiguiendo los siguientes resultados:
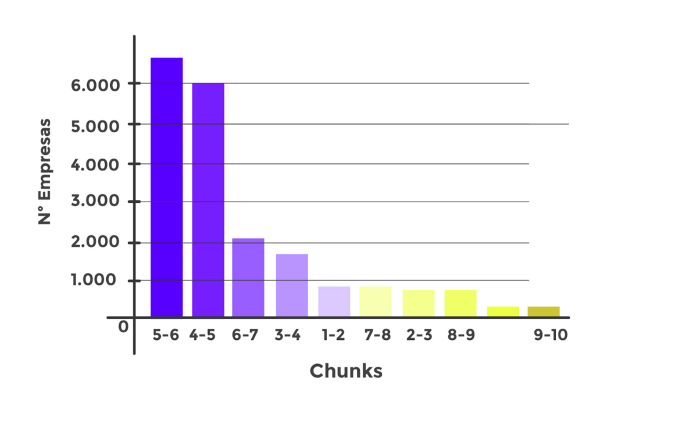
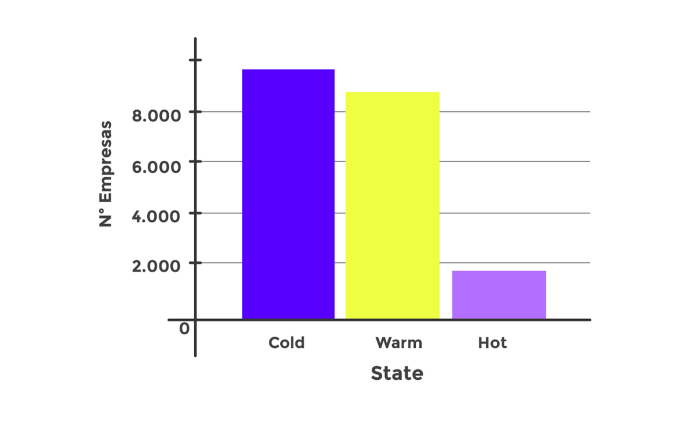
Conclusiones
Finalmente, devolvemos el mismo DataFrame al cliente donde cuenta con 4 columnas adicionales: Clusters, Scoring, Chunks y State.
Con los Clusters serán capaces de analizar cada segmento resultante y focalizarse en ellos en función de las necesidades.
Con las columnas de Scoring, Chunks y State el Call Center podrán comenzar a captar a aquellas empresas que tengan una mejor nota y sean más proclives a convertirse en clientes, sin necesidad de realizar una investigación exhaustiva, por lo que se ahorrará muchos recursos.
Además, con la combinación de Clusters y Scoring contarán con la posibilidad de seleccionar a las empresas con mejores notas, excluyendo o añadiendo los segmentos pertinentes, por ejemplo, en época de crisis inmobiliaria podrán excluir los segmentos del sector de la construcción y similares centrándose en los restantes segmentos por nota.
Por último y no menos importante, se entrega al cliente una base de datos completa que en principio contaba con una gran cantidad de valores nulos. Esta inferencia realizada con el algoritmo KNN ayudará a nuestro cliente a hacerse una idea de las características de las empresas donde faltaban datos y podrá así focalizar su captación hacía Leads con características similares.
Todas estas posibilidades generarán una optimización de recursos donde la captación de Leads se verá enormemente acelerada y la reducción de costes también marcará la diferencia, pudiendo reorientar esos gastos.
En APACHE luchamos día a día para ofrecer los mejores servicios y diferenciarnos de la competencia.
Es por ello por lo que nos encanta realizar soluciones disruptivas de la mano de las últimas tecnologías, utilizadas de forma creativa e inteligente.


